[FILIP review] Fine-grained Interactive Language-Image Pre-Training
Author
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, Chunjing Xu
1. INTRODUCTION
본 논문에서는 기존에 등장했던 VLP(Vision Language Pre-Training) 방법론인 CLIP과 ALIGN에 대해 시사하며 글을 시작한다.
CLIP과 ALIGN은 인터넷에서 수집한 수백만 개의 image-text pair에서 Vision, Text Representation을 학습하고, 뛰어난 zero-shot샷 능력과 robust함 통해 다양한 Vision - Language DownStream Task에서 성공을 거두었다. 특히 이러한 모델의 핵심 기술은 dual stream model을 활용해 이미지와 텍스트를 전체적으로 보고 Contrastive 학습을 하는 데에 있다.
그러나, 이 모델들은 이미지와 텍스트 사이의 세부적인 정보를 잘 포착하지 못한다.

예를 들어, 위와 같은 동물원 이미지에서 "사자 옆의 작은 다람쥐가 앉아 있는 귀여운 모습"이라는 텍스트 pair가 있다고 할 때, CLIP과 ALIGN은 전체 이미지와 전체 텍스트를 전역적으로 비교해 일반적인 연결고리를 찾는다. 즉, 이미지에 사자가 포함되어 있고, 텍스트에서 사자에 대해 언급하는지를 확인한다.
결과적으로 이러한 모델들은 이미지에서 객체를 인식하고 텍스트와 연결시킬 수는 있지만, 텍스트에서 언급된 “작은 다람쥐”와 “앉아 있는 귀여운 상황”을 구체적으로 연결하는 데에는 제한적일 수 있다.
따라서 FILIP은 이러한 한계를 극복하기 위해 더 세밀한 크로스 모달 상호 작용을 구현하는 새로운 접근 방식인 Fine-grained Interactive Language-Image Pre-Training을 제안한다.
FILIP은 세밀한 수준의 image-text 상호작용을 모델링한다. 기존의 세밀한 상호작용 방법들은 주로 두 가지 방식으로 나뉜다.
- 사전 학습된 객체 탐지기 사용이미지에서 ROI feature를 추출하고, 이를 텍스트와 융합하는 방식이다. 그러나, 이 방식은 많은 ROI feature를 미리 계산하고 저장해야 하며, 제한된 클래스 수와 객체 탐지기의 성능에 의존하여 zero-shot 학습 능력이 제한될 수 있다.
- 토큰 수준의 상호작용 모델링이미지와 텍스트 각각의 패치 또는 토큰을 동일한 공간으로 매핑하고, cross-attention이나 self-attention을 사용하여 상호작용을 모델링하는 방식이다. 그러나 이 방법은 학습 및 추론 시에 효율성이 떨어진다. 특히 cross-attention은 복잡한 구조가 필요하고, self-attention은 시퀀스 길이가 길어질수록 계산 복잡도가 증가한다.
FILIP은 이러한 문제를 해결하기 위해, cross-modal contrastvie loss를 사용하는 새로운 방식의 the fine-grained semantic alignment 방법을 채택한다.
FILIP은 이미지와 텍스트 인코더 간의 세밀한 상호작용을 통해 the fine-grained semantic alignment을 이끌어내도록 설계되었다. 이미지를 여러 패치로 나누고, 텍스트를 여러 단어로 나눈 후, 이 패치와 단어 각각의 유사성을 최대화하는 방식으로 학습을 진행한다. 이렇게 하면 이미지와 텍스트 간의 세밀한 contrastive한 관계를 학습할 수 있다.
3. METHOD
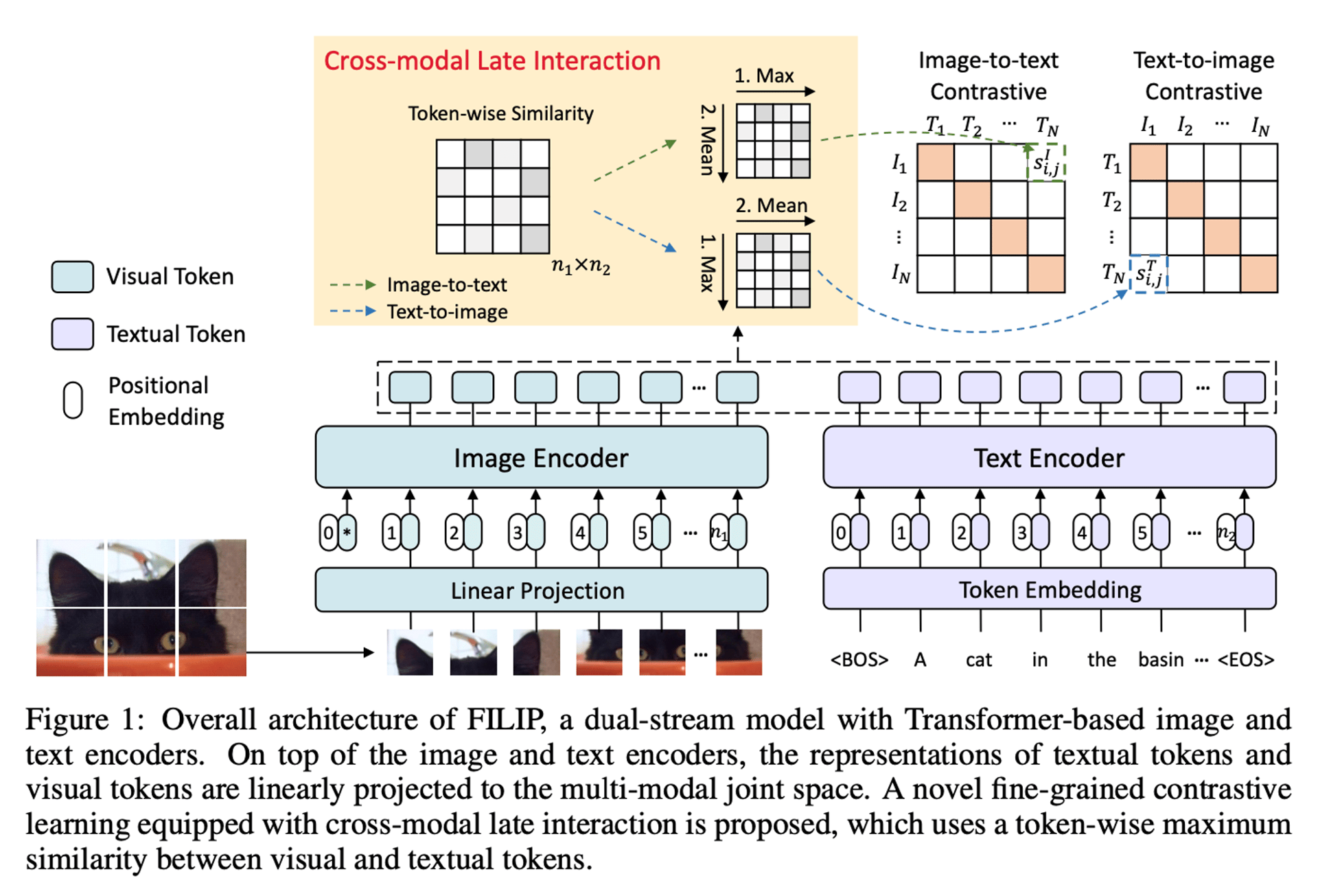
다음은 FILIP의 중 4가지 특징이다.
- FILIP은 이미지와 텍스트 인코더를 각각 따로 사용하는 dual stream model이다. 이는 이미지와 텍스트의 정보를 별도로 처리한 후, 하나의 공통된 다중 모달 공간으로 투영한다.
- visual modality에서는 이미지 인코더로 ViT가 사용된다. 이미지를 여러 패치로 나누고, 추가적인 [CLS] 토큰과 함께 인코더에 입력한다. 이 방식은 이미지를 더 작은 부분으로 나누어 처리하는 데 유리하다.
- textual modality에서는 텍스트를 토큰화하기 위해 Byte Pair Encoding(BPE) 방식을 사용한다. 텍스트 시퀀스는 [BOS] 토큰으로 시작하고 [EOS] 토큰으로 끝난다.
- 마지막으로 cross-modal 상호작용이다. 텍스트와 이미지 인코더에서 나온 표현들은 선형적으로 공통된 다중 모달 공간으로 투영되며, 이후 각각 L2 정규화된다. 기존의 듀얼 스트림 모델(CLIP과 ALIGN)은 이미지와 텍스트 전체의 전역적인 특징만을 이용한 반면, FILIP은 이미지 패치와 텍스트 토큰 간의 세밀한 상호작용을 고려하는 새로운 contrastive 학습 목표를 도입한다. 이를 통해 더 상세한 의미 정렬이 가능하다.
이렇게 함으로써 FILIP은 이미지와 텍스트 사이의 더 깊고 세밀한 semantic 연결을 학습할 수 있다.
3.1 FINE-GRAINED CONTRASTIVE LEARNING
일반적인 contrasitve representaion learning은 아래와 같이 정의 된다.

contrastive learning은 인코딩된 표현에 대해 연관성이 있는 샘플은 가깝게 그리고 연관이 없는 샘플에 대해서는 멀리 떨어지게 훈련된다.
cross-modal contrastive learning에서는 이미지 데이터와 텍스트 데이터를 각가 처리하는 두 개의 인코더 (fθ, gφ)를 학습하는 것이 목표이다.

학습 과정에서 각 훈련 배치 내에서의 b개의 image-text pair를 가져오게 될 경우 이미지를 기준으로, s_{k, k}^I는 Positive Sample이고 s_{k, j}^I의 경우 Negative Sample이다.

마찬가지로 Text의 기준에서도 위의 공식으로 정리가 된다.
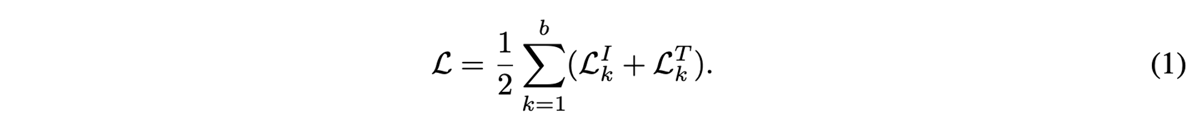
이럴 경우 미니 배치내의 Total Loss는 위와 같이 정의가 가능하다.
3.1.1 CROSS-MODAL LATE INTERACTION
여기서 Cross Modal Late Interaction이란 이미지와 텍스트 간 상호작용을 보다 세밀하게 분석하기 위한 방법론이다. 기존의 CLIP, ALIGN 등의 방법들은 이미지나 텍스트 전체를 하나의 큰 특징으로 요약해 관계를 분석했지만, FILIP은 이미지와 텍스트 각각을 더 작은 단위로 쪼개 각 이미지 조각과 텍스트 조각 사이의 최대 유사도를 계산한다.

예를 들어, 위 그림에서 첫 번째 조각에서는 검은 고양이의 귀라는 텍스트 시퀀스와 가장 유사도가 높을 것이다. 이렇게 각 조각 사이에서 가장 높은 유사도를 찾아내 전체 이미지와 텍스트 사이의 유사도를 평균내 결정한다.
이를 통해 미묘한 연결고리나 세부적인 차이점도 발견할 수 있고 전체 이미지와 텍스트 대신 중요한 부분만을 선택해 처리하면서 메모리 사용량이나 계산 시간도 절감할 수 있다.
이제 이미지와 텍스트 각각을 토큰(token)으로 나누고, 이들 사이의 유사성을 계산하는 공식은 다음과 같다.
기존 모델인 CLIP과 ALIGN은 각각의 이미지나 텍스트를 global feature로 인코딩하고, 그 특징들 간의 유사성을 다음과 같이 내적을 통해 계산한다.
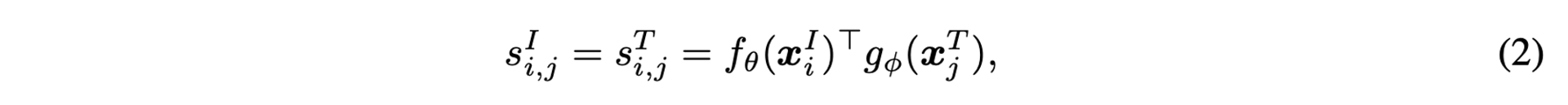
하지만 이는 포지셔널 인코딩에 적용되는 세밀한 word-patch 정렬을 무시한다.
FILIP은 더 세밀한 상호작용을 반영하기 위해, 토큰 단위의 최대 유사성(maximum similarity)을 사용한다. 이미지 xiI와 텍스트 xjT의 각 토큰 간의 유사성을 계산한 후, 각 토큰에서 가장 큰 유사성을 취한다. 이 값은 해당 토큰이 텍스트와 가장 잘 맞는 부분을 나타낸다.
k-번째 이미지 토큰과, 텍스트 xjT의 모든 토큰 사이의 유사성 중 최대값은 공식 3과 같이 계산된다.
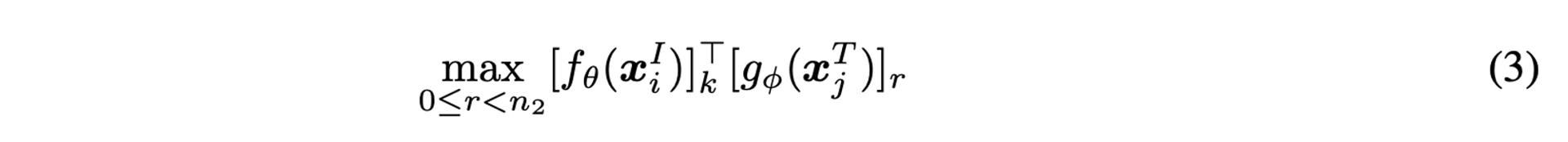
이때, n1은 Image patch의 갯수, n2는 패딩 되지 않은 텍스트 토큰이라고 가정할때,

이와 같은 차원으로 구성된다고 한다.
이렇게 계산된 토큰 단위의 최대 유사성들을 평균내어 이미지와 텍스트 간의 전체 유사성 si,jI를 구한다.
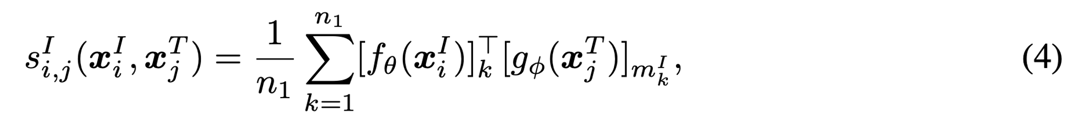
이때 m은 k-번째 이미지 토큰에 대해 가장 유사한 텍스트 토큰의 인덱스이다.

텍스트의 경우도 같으며 동일하게 진행된다.
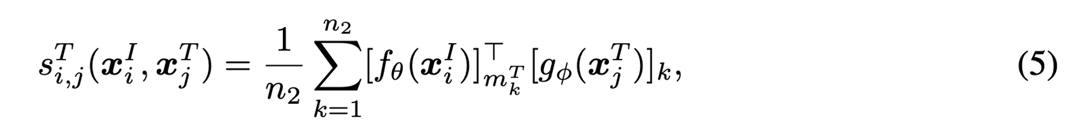

3.1.2 PROMPT ENSEMBLE AND TEMPLATES
- 텍스트 템플릿의 경우 CLIP에서와 같이 “a photo of a {label}.”의 라벨을 사용한다.
- 논문에서는 “a photo of a {label}.”의 템플릿만 사용되지만, 실험으로 여러 프롬프트를 앙상블 하여 사용하게 된다. 이때 앙상블의 기준은 각 프롬프트 템플릿에 대해 토큰별 유사성의 평균을 이용한다.
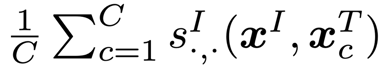
3.2 IMAGE AND TEXT AUGMENTATION
FILIP은 모델의 효과를 극대화하기 위해 모델의 pre-training 단계에서, 이미지와 텍스트 데이터 모두에 데이터 증강을 적용하였다. 또한, FILIP300M이라는 대규모 데이터셋을 새로 구축하여 임의의 규칙에 따라 필터링을 적용하였다.
이미지 증강 및 필터링
- AutoAugment 방식으로 이미지를 자르거나 회전, 색상조절 등의 방법을 사용해서 증강
- 너비나 높이 중 짧은 쪽이 200 Pixel보다 작은 이미지는 제거
- 이미지의 가로 세로 비율이 3을 초과하는 경우도 제거
텍스트 증강 및 필터링
- 역번역 방식(back-translation)으로 원문을 다른 언어로 번역한 후 다시 원래의 언어로 번역하는 과정을 거침
- 각 이미지-텍스트 쌍에 대해 원본 텍스트와 두 개의 역번역된 텍스트 총 세 개의 텍스트 생성
- 영어 텍스트만 유지하고, 의미가 없는 텍스트(예: "img 0.jpg")는 제외
- 텍스트가 10번 이상 반복되는 이미지-텍스트 쌍도 제거
3.3 PRE-TRAINING DATASET
- CLIP 및 ALIGN은 각각 400M, 1800M으로 구성된 Image-Text Pair를 사용하였지만 FILIP는 300M으로 구성된 Image-Text로 구성된다.
- 또한 Conceptual Captions 3M(CC3M), Conceptual 12M(CC12M) 및 Yahoo Flickr Creative Commons 100M(YFCC100M)을 포함한 3개의 공개 데이터 세트 도 사용됩니다. 사전 훈련에는 약 3억 4천만 개의 이미지-텍스트 쌍이 사용된다.
4. EXPERIMENTS
4.2 ZERO-SHOT IMAGE CLASSIFICATION
FILIP 모델을 사용한 zero-shot 이미지 분류 작업 평가이다.
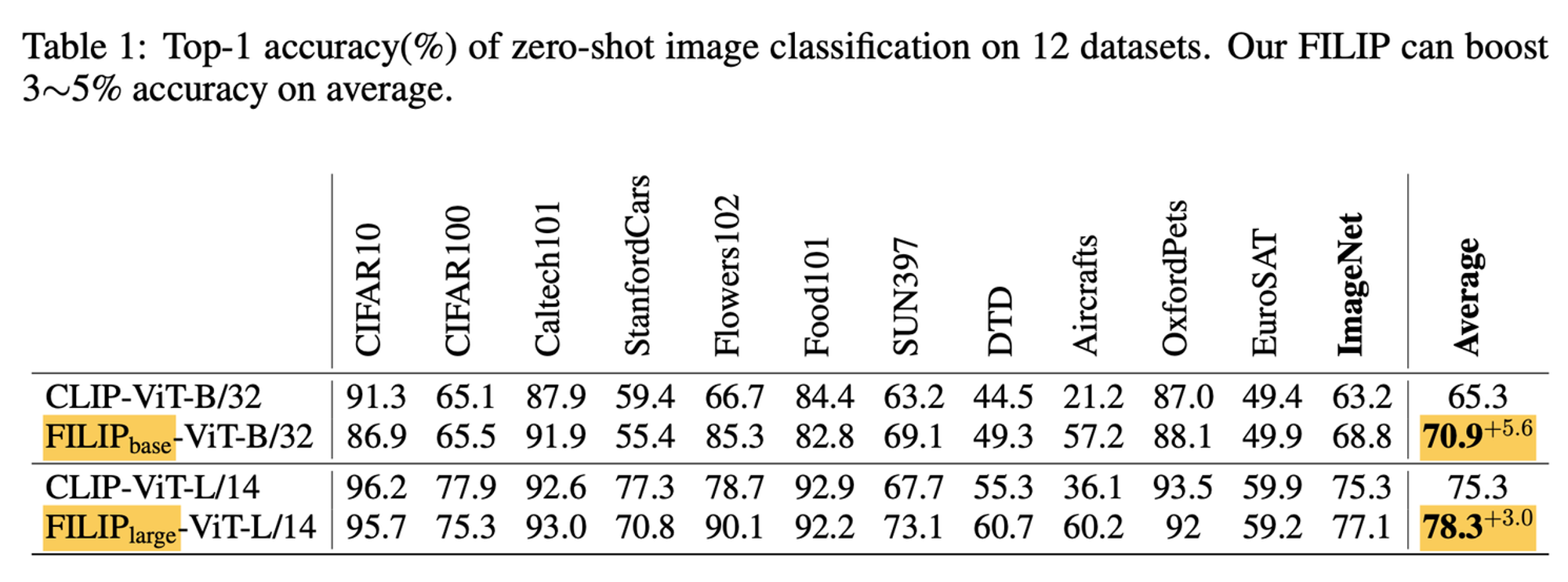
12개의 하위 분류 데이터셋에서 FILIP 모델은 CLIP 모델보다 평균적으로 높은 정확도를 보였으며, 특히 이미지넷 같은 대규모 데이터셋에서 뛰어난 성능을 나타내었다.
4.3 IMAGE-TEXT RETRIEVAL


FILIP 모델의 성능을 평가하기 위한 또 다른 실험은 image text retrieval(검색)이다. 이 작업은 두 가지 하위 작업으로 나뉘는데, 이미지에서 텍스트를 검색하는 작업과 텍스트에서 이미지를 검색하는 작업이다.
두 가지 검색 벤치마크 데이터셋(Flickr30K, MSCOCO)에서 FILIP의 zero-shot 성능과 fine-tuning 시의 성능을 비교하였다. 대부분의 task에서 성능 향상이 일어났지만, 특히 zero-shot으로의 image-to-text 성능이 매우 향상되었다.
4.4 ABLATION STUDY

Ablation Study에서는 각 구성 요소를 개별적으로 제거하거나 변경할 때 모델의 성능이 어떻게 달라지는 지를 관찰하였다. FILIP base 모델을 사용하여 YFCC100M 데이터셋의 필터링된 부분집합으로 훈련을 수행하고, MSCOCO 데이터셋에서 제로샷 이미지-텍스트 검색과 ImageNet에서 제로샷 분류 작업으로 모델의 성능을 측정했다.
세 구성요소를 조정함으로써 Raw Image 내에서 텍스트가 원하는 이미지의 세부 부분을 정확히 찾아내는 반면 CLIP은 좀 부족한 걸 볼 수 있다. 이를 통해서도 FILIP의 이미지, 텍스트간 이해도가 높다는 걸 확인할 수 있다.

다양한 설정으로 훈련하였지만, 신기하게 256 임베딩 사이즈가 제일 좋은 성능인것은 조금 특이하다.
4.5 VISUALIZATION OF FINE-GRAINED ALIGNMENT

토큰별 유사성을 기반으로 각 패치의 대한 유사성을 확인하였다. CLIP은 유사성이 없는 반면 FILIP은 확인이 뚜렷하게 된다.
5. CONCLUSION AND FUTURE WORK
기존의 방법론이었던 CLIP, ALIGN의 이미지-텍스트 이해도가 종합적인 내용은 고려하지만, 세부적인 내용은 고려하지 못함을 지적하며 Cross Modal Late Interaction 방법론인 FILIP을 제안하였다.
- 이미지는 ViT encoder를 통해 입력, 세부적으로 쪼개서 각 조각 이미지와 텍스트 시퀀스 간 유사도 계산, 일반적인 이미지 증강
- 텍스트는 transformer encoder를 통해 입력, [BOS]와 [EOS] 사이의 텍스트 시퀀스가 나오도록 설정, 역번역 증강
임의의 필터링 규칙을 통해 300M의 이미지-텍스트 쌍 데이터셋을 활용해 사전학습을 하였다.
제로샷 이미지 분류, 이미지-텍스트 검색, Ablation Study 등 다양한 실험을 하였고 특히 zero-shot 이미지 분류, 검색 등 zero-shot 성능이 탁월하다.
앞으로 text encoder에 MLM 기법을 적용할 수 있고, image encoder 개선을 통해 추가 성능 향상을 노려볼 수 있다.
Reference
https://www.notion.so/FILIP-Fine-grained-Interactive-Language-Image-Pre-Training-f4d9772588b0495f9a978ccb07bf32d8?pvs=4#bf57224a82af4b6db3d9efe06d351b02
https://www.notion.so/FILIP-Fine-grained-Interactive-Language-Image-Pre-Training-f4d9772588b0495f9a978ccb07bf32d8?pvs=4#f1109979e3394b488dc891a9a026d7c2
https://www.notion.so/FILIP-Fine-grained-Interactive-Language-Image-Pre-Training-f4d9772588b0495f9a978ccb07bf32d8?pvs=4#0fea42537c7b4111bfae2cdcfafecd18
https://www.notion.so/FILIP-Fine-grained-Interactive-Language-Image-Pre-Training-f4d9772588b0495f9a978ccb07bf32d8?pvs=4#f4aadd98892a41f1b8022c328ac183ed