deep learning paper/multi-modal
[DeCLIP review] Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
SUIN2
2024. 7. 12. 01:00
Author
Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, Junjie Yan
Abstract
- 최근, 대규모의 CLIP(Contrastive Language-Image Pre-training)은 zero-shot 인식 능력과 downstream task 전이 가능성으로 엄청난 주목을 받고 있다.
- 하지만, CLIP은 4억개의 image-text pair를 pre-training에 필요로 하여, 많은 데이터를 요구한다.
- 본 연구는 이러한 제한을 완화하기 위해, 새로운 학습 패러다임인 Data efficient한 CLIP을 제안한다.
- image-text pairs 사이의 광범위한 supervision을 신중하게 활용하여 DeCLIP이 일반적인 시각적 특징을 더 효과적으로 학습할 수 있음을 보여준다.
- 단일 image-text contrastive supervision을 사용하는 대신에, 다음과 같은 방법을 통해 데이터 잠재력을 완전히 활용한다.
- 각 modality 내의 self-supervision(SS)
- modality에 걸친 multi-view supervision(MVS)
- 다른 유사한 pair의 nearest-neighbor supervision(NNS)
- 이러한 본질적인 supervision으로, DeCLIP-ResNet50은 적은 데이터를 사용하면서, ImageNet에서 60.4%의 zero-shot top1 정확도를 달성할 수 있었다.
1. Introduction
- 일반적으로, CV model은 미리 정의된 객체 카테고리의 고정된 set를 예측하기 위해 pre-training 된다.
- 그러나, 이 supervised pre-training은 새로운 시각적 개념을 지정하기 위해 힘든 인간의 라벨링이 필요하기 때문에 확장이 어렵다.
- NLP에서의 pre-training은 본질적인 supervision이 pre-training을 확장 가능하게 만든다.
- 따라서, 연구자들은 시각적 특징을 배우기 위해 자연어 supervision을 사용한다.
- language-image pre-training은 매우 큰 크기로 확장할 수 있으며, 인터넷의 풍부한 image-text pair을 활용할 수 있다.
- CLIP과 ALIGN은 일치하지 않은 image-text pair의 매핑을 위해 contrastive loss을 채택한다.
- 이 모델들은 4억/10억 개의 image-text pair을 포함하는 거대한 데이터 셋을 학습함으로써 높은 성능을 달성한다.
- 하지만, 이러한 방법은 거대한 저장 및 컴퓨팅 자원을 필요로 한다.
- 또한, 광범위한 supervision은 간과하면서 단일 image-text contrastive supervision만 사용하므로 비효율적이다.
- 먼저, 각 modality 내에서 풍부한 구조적 정보의 기초가 있다.
- 게다가, multi-view supervision을 multi-modality 설정으로 더 확장한다.
- 이러한 간과된 supervision 외에도, 다른 유사한 pair의 새로운 NN(nearest-neighbor)을 제안한다.아래의 그림처럼, ’going to see a lot of vintage tractors this week’는 ’vintage at tractors a gathering’로 설명될 수 있다.

이러한 이유로 임베딩 공간에서 NN을 샘플링하고, 추가적인 supervisory signal로 활용한다.

- ResNet50 이미지 인코더와 transformer 텍스트 인코더를 사용하여, 7.1배 적은 데이터로, CLIP-ResNet50보다 ImageNet에서 60.%의 zero-shot top1 정확도를 달성하였다.
- 또한, DeCLIP-ResNet50은 11개의 시각적 데이터 셋 중 8개에서 성능을 능가했다.
- Contributions
- self-supervision과 cross-modal Multi-View Supervision의 첫 연구이다. 이 연구는 데이터를 확장하는 대신, multi-modal data 내에서 본질적인 supervision을 완전히 활용하기 위한 새로운 방향을 열어준다.
- 다른 유사한 pair의 정보를 활용하기 위해, 새로운 cross-modal NNS(Nearest-Neighbor Supervision)을 제안한다. 또한, NNS는 의미론적 수준의 증강으로 간주될 수 있다.
3. Approach
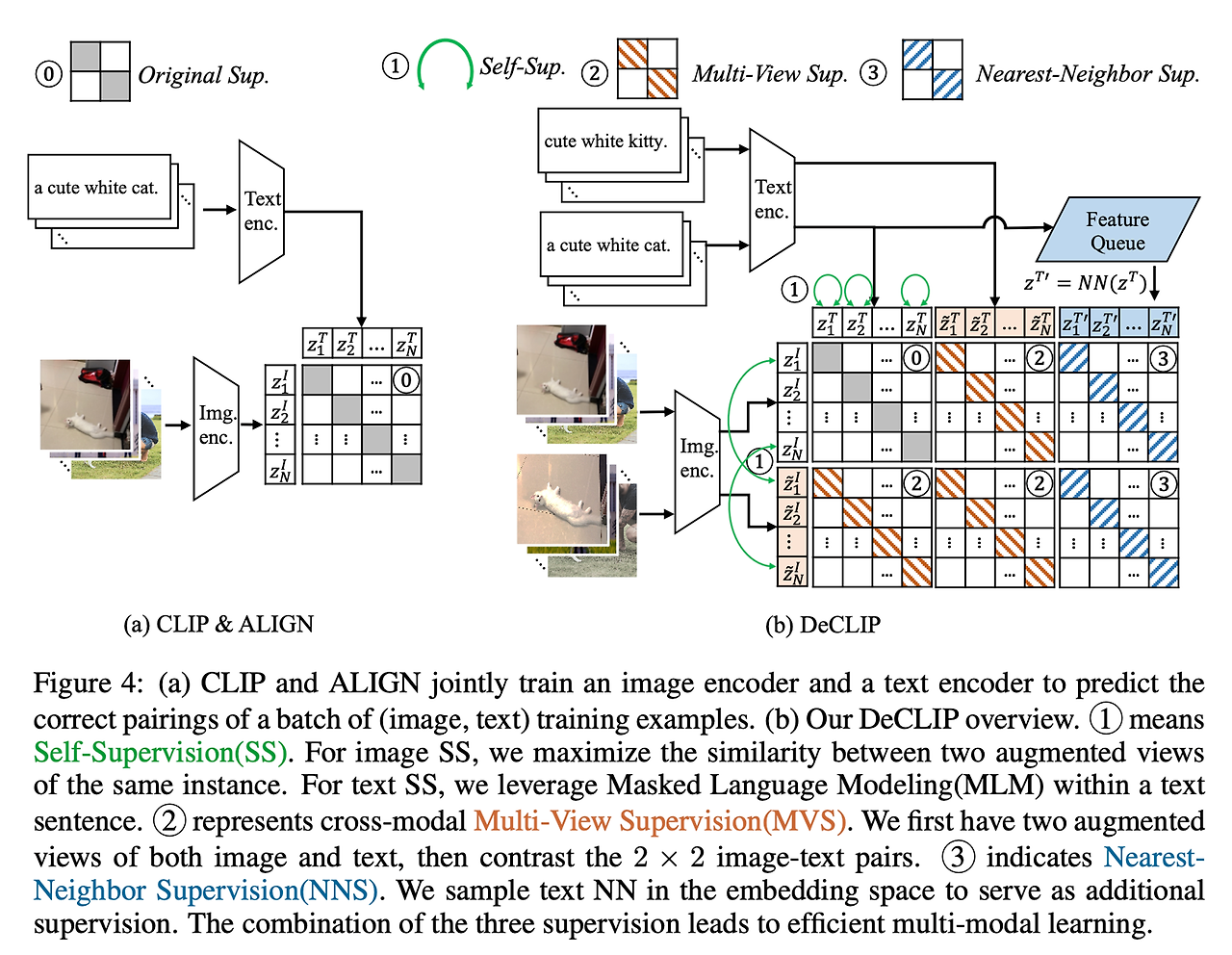
3.2 Overview of DeCLIP
- (b)에서처럼, DeCLIP은 세 개의 추가적인 supervisory signal을 사용한다.
- modality 내에서 기존 방법을 사용하여, 이미지와 텍스트 self-supervision(SS)을 사용한다.
- image SS를 위해, 간단하면서도 효과적인 SimSiam을 채택한다. ovjective는 두 개의 증강 이미지 피처 사이의 유사성을 극대화하는 것이다.
- text SS를 위해, 널리 사용되는 MLM(Masked Language Modeling을 pre-text task로 채택한다.
- SS는 단일 modality에만 초점을 두는 반면, 우리는 더 나아가 cross-modal Multi-View Supervision(MVS)를 제안한다.
- 이미지와 텍스트 모두에 확률적 데이터 증강을 적용하여 각 예제의 두 가지 상관 view를 만든다.
- 그런 다음, image-text 대비 손실은 모두 2 x 2 pair에 대해 계산된다.
- CLIP은 텍스트 증강을 사용하지 않고, 무작위 정사각형 자르기 이미지 증강만 사용하므로 데이터가 부족하다.
- 유사한 텍스트 설명을 잘 사용하기 위해 임베딩 공간에서 채굴한 새로운 Nearest-NeighborSupervision(NNS)를 제안한다.
- 구체적으로, 전체 데이터 분포를 대표하는 FIFO(first-in-first-out feature) queue를 유지한다.
- 의미적으로 유사한 텍스트 설명을 얻기 위해 임베딩 공간에서 nearest-neighbor 검색을 사용한다.
- 그런 다음, 추가적인 supervision을 받기 위해 image-text contrastive loss를 사용한다.
3.3 Supervision exists Everywhere
Self-Supervision within each modality(SS)

- (a)를 보면, 각 이미지에 대해 두 개의 증강 view(𝑥𝐼, 𝑥̃𝐼)를 이미지 인코더로 보낸다.
- 인코더의 표현 품질을 개선하기 위해 일반적으로 2-layer MLP인 비선형 예측 모듈을 사용한다.
- 목표는 이 논문에서 부정적인? 코사인 유사성인 𝑧̃와 p^I사이의 유사성을 극대화하는 것이다.
- (b)를 보면, text self-supervision을 위해 BERT의 MLM 방법을 따른다.

Multi-View Supervision(MVS)
- CLIP에서는 원본 텍스트(증강 제외)를 이미지의 단일 ‘global view’만을 contrastive한다.
- 하지만, 이미지의 텍스트 설명은 전체 그림을 묘사하지 않을 수 있으며, 대신 이 이미지의 작은 local view만을 묘사한다.
- 예를 들어, 그림 4의 “a cute white cat”라는 텍스트가 있는 이미지에서 볼 수 있듯이, 중앙 개념(고양이)은 그림의 작은 부분만 차지한다.
- 이 불일치를 완화하기 위해, 우리는 local을 자세히 살펴보고, 그림 4의 (b)의 증강 view에서 볼 수 있듯이 보조 supervision으로 활용한다.
- 그것을 multi-modal 설정으로 더 확장한다.
- 보다 구체적으로 작은 local view를 얻기 위해, RandomResizedCrop법이 포함된 SS에 도입된 두 개의 이미지 view를 재사용한다.
- 텍스트의 경우, 문장의 전반적인 의미론적 의미를 이해하는 것이기 때문에, 두 개의 text view를 생성하기 위해 텍스트 분류 증강 EDA를 채택한다.
- (𝑧𝐼, 𝑧𝑇) 사이의 원래 대조 손실 외에도, (𝑧𝐼, 𝑧̃𝑇), (𝑧̃𝐼, 𝑧𝑇), (𝑧̃𝐼, 𝑧̃𝑇)를 contrastive하여 3배의 다양하고 고품질의 추가 supervision으로 이어질 수 있다.
- z^I는 이미지, z^T는 텍스트의 정규화된 임베딩
Nearest-Neighbor Supervision(NNS)
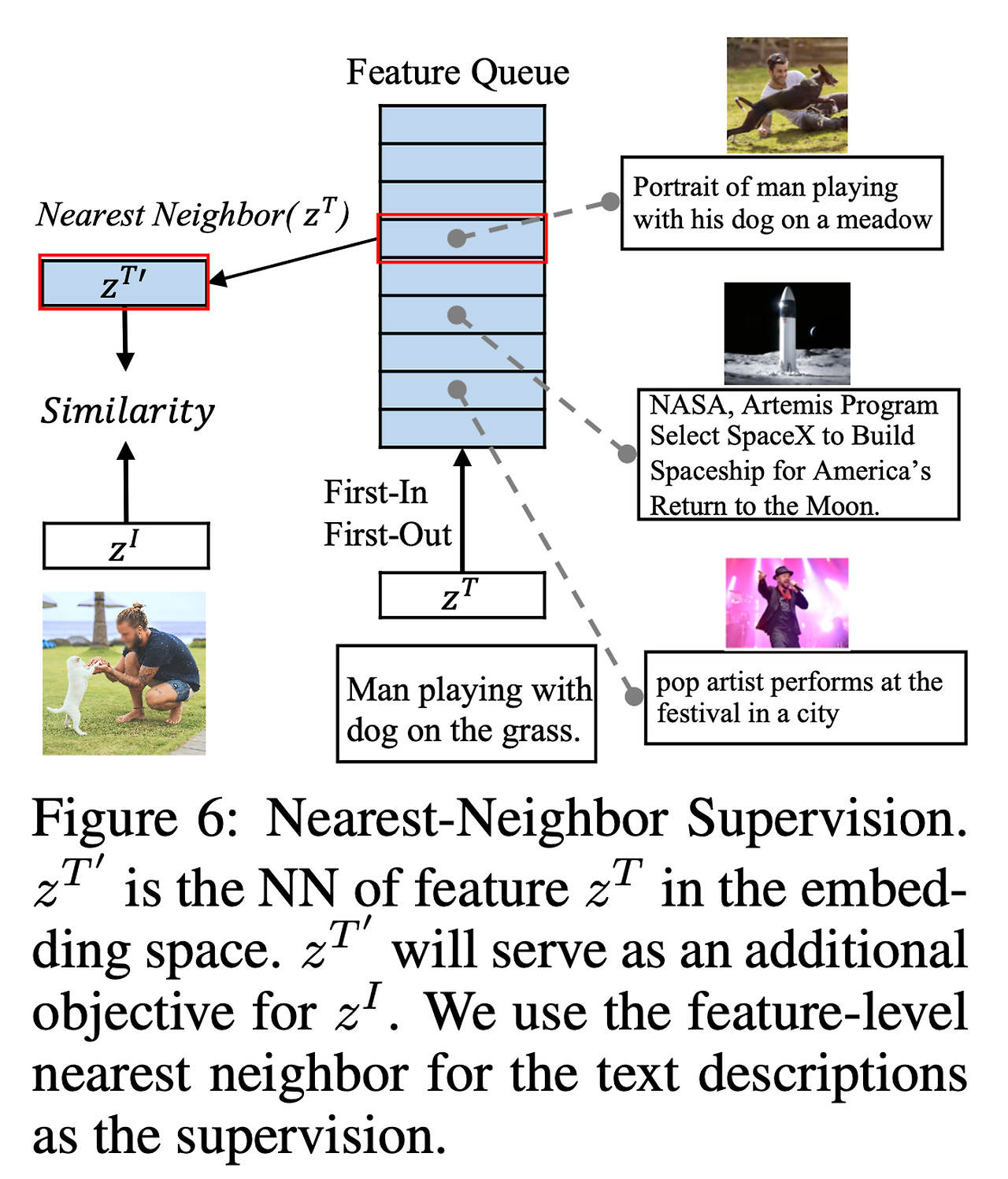
- 그림 3을 보면, 한 이미지는 데이터 셋 중 다른 유사한 텍스트 설명을 가질 가능성이 있다.
- 다른 pair의 정보를 활용하고 단일 pair을 넘어서기 위해, 더 다양한 supervision을 얻기 위한 NN(nearest-neighbor)을 사용할 것을 제안한다.
- 공식적으로, 임베딩 공간에서 텍스트 특징 z^T의 NN 특징 z^{T'}를 찾는 것을 목표로 한다.
- 두 특징 사이의 거리는 간단한 코사인 유사성에 의해 측정될 수 있다.
- 전체 백만 규모의 데이터 세트에서 NN을 검색하는 것은 불가능하다.
- 따라서 전체 데이터 분포를 시뮬레이션하기 위해 FIFO queue Q를 유지한다.
- 그림 6을 보면, (𝑧𝐼, 𝑧𝑇′)사이의 더 contrastive loss를 얻는다.
- 두 개의 증강된 이미지 특징이 있기 때문에, (𝑧̃𝐼, 𝑧𝑇′) 사이의 contrastive loss도 계산한다.
- DeCLIP의 전체 loss function은 다음과 같다.
- L_{ISS}: image SS loss
- L_{TSS}: text SS loss
- L_{MVS}: multi-view loss
- L_{NNS}: nearest-neighbor loss

4. Experiments

- DeCLIP(Our pred)은 전체 객체를 분할하는 반면, CLIP은 몇 가지 구성 요소만 본다.

- 첫 번째 행은 원본 image-text pair이고, 두 번째 행은 NN pair이다.
- 일반적으로 NN pair에서 텍스트가 비슷한 지적 의미를 가지고 있다는 것을 알 수 있다.
- 따라서 NN pair은 고품질의 supervision을 제공할 수 있다.
5. Conclusion
- 본 논문은 Data efficient CLIP 패러다임인 DeCLIP을 소개한다.
- 더 광범위하고 확장 가능한 supervision을 통해 시각적 표현을 배우는 것이 목표이다.
- 특히, 단일 image-text contrastive supervision을 사용하는 대신 다음과 같은 방법으로 데이터 잠재력을 완전히 활용한다.
- 각 modality 내의 self-supervision(SS)
- modality에 걸친 multi-view supervision(MVS)
- 다른 유사한 pair의 nearest-neighbor supervision(NNS)
- 실험적으로, DeCLIP은 다양한 유형의 신경망(CNN, ViT)과 다양한 양의 데이터로 우수한 효과와 효율성을 보여준다.